Inside the Black Box: The Architecture of LLMs from Tokenization to Inference
It isn’t magic. It’s probability, linear algebra, and architecture. Here is the mechanism behind the API calls.
TL;DR
Most developers treat AI as a "black box", we send a JSON payload to an API and get a string response. This article breaks down what happens inside that box: from tokenization and vector embeddings to the Transformer architecture and the probability math that powers "next token prediction."
Introduction
As software engineers, we are used to deterministic systems. If a = 5 and b = 5, then a + b will always equal 10.
AI, specifically Large Language Models (LLMs), works differently. It is probabilistic, not deterministic. We have all integrated OpenAI or other AI APIs into our applications, built RAG pipelines, and optimized system prompts. But very few developers understand the underlying mechanics of how the model generates an answer.
Understanding the architecture of these models is not just for data scientists. As Engineers, knowing how the engine works helps us optimize costs, reduce latency, and debug hallucinations more effectively.
Here is the technical breakdown of how AI models work, stripped of the marketing fluff.
1. The Core Concept: Next Token Prediction
At its simplest level, an LLM is a prediction engine. It does not "know" facts; it knows the statistical probability of which word (token) comes next in a sequence.
If you input: "The quick brown fox..." The model calculates the probability of every possible next word in its vocabulary.
-
jumps: 85%
-
walks: 10%
-
sleeps: 5%
It selects "jumps" and appends it to the sequence. Then it runs the calculation again for "The quick brown fox jumps..." to find the next word. This loop continues until it hits a "stop token."
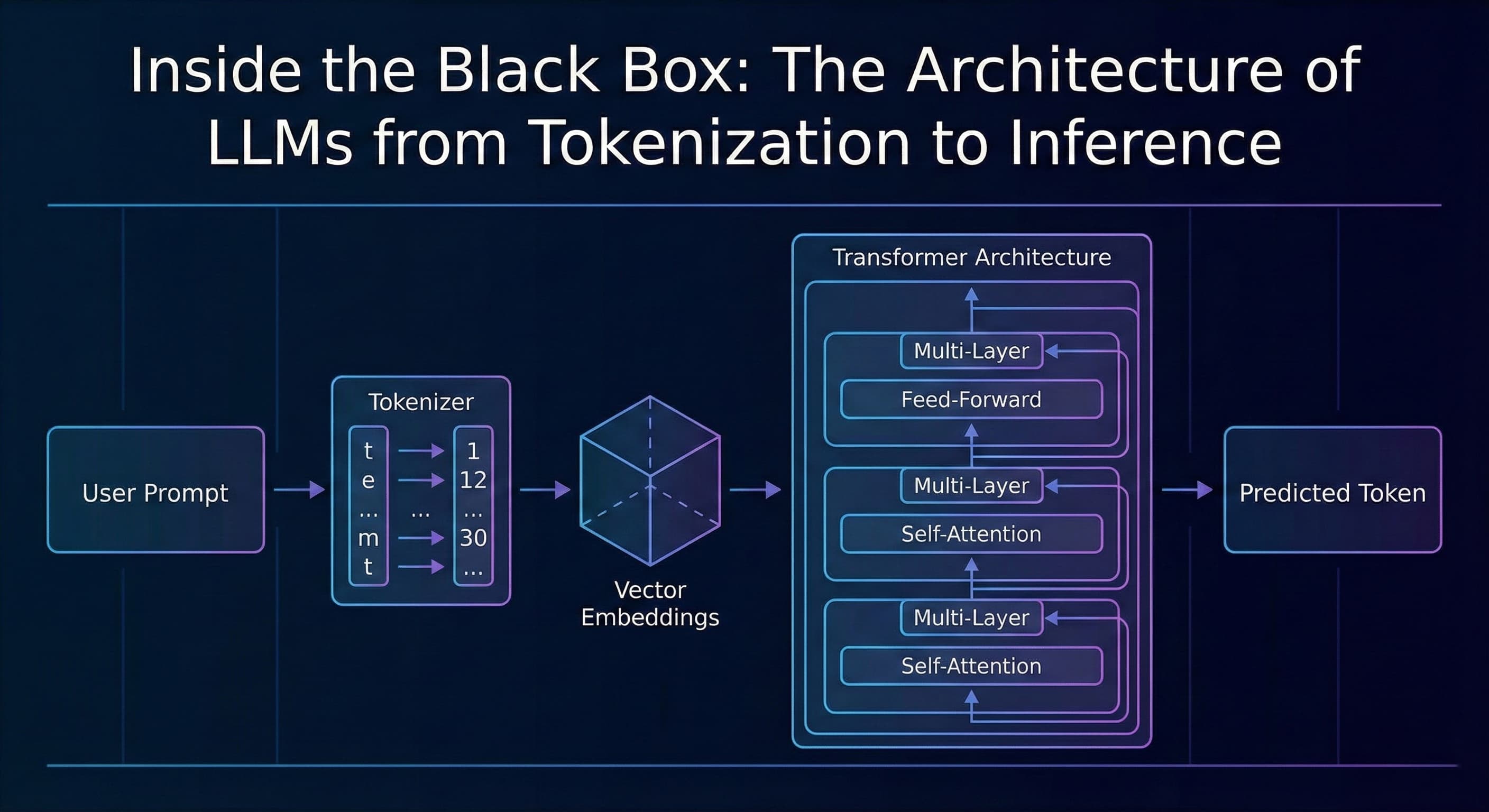
2. Tokenization: The "Compiler" of AI
Models do not understand English or any other language. They understand numbers. Before your prompt hits the neural network, it goes through a Tokenizer.
Tokenization breaks text into smaller chunks called tokens. A token can be a word, part of a word, or a character.
-
Input:
building -
Tokens:
build(1456) +ing(231)

This converts your text string into an array of integers. This is why AI providers charge by the token, you are paying for the compute required to process these integer arrays.
3. Embeddings: Turning Numbers into Meaning
An array of numbers [1456, 231] is useless without context. The model needs to understand that "King" is related to "Queen" in the same way "Man" is related to "Woman."
This is done using Embeddings. The model plots every token into a multi-dimensional vector space (often thousands of dimensions). In this geometric space:
-
Words with similar meanings are close together (e.g., "Apple" and "Banana").
-
Words with different meanings are far apart.

This vectorization allows the model to understand semantic relationships mathematically. It calculates the "distance" between concepts using linear algebra (usually Cosine Similarity).
4. The Transformer Architecture (The Engine)
The breakthrough that made modern AI possible is the Transformer architecture, introduced by Google in 2017. The key component of the Transformer is the Attention Mechanism.
In older models, if you wrote a long paragraph, the model would "forget" the beginning by the time it reached the end. The Attention Mechanism solves this by allowing the model to look at every token in the sequence simultaneously and decide which ones are important.
Example: "The bank of the river was muddy."
When processing the word "bank," the Attention mechanism looks at the surrounding words. It sees "river" and "muddy," so it assigns a high "attention score" to those words. This tells the model that "bank" here refers to land, not a financial institution.

5. Training: How the Model Learns
How does the model know that "jumps" follows "fox"? Through massive training phases:
-
Pre-Training (The Knowledge Base): The model is fed terabytes of internet text. It plays a game of "fill in the blank" billions of times. It adjusts its internal parameters (weights) every time it guesses wrong. This is computationally expensive and takes months.
-
Fine-Tuning (Instruction Following): A raw pre-trained model is chaotic. It simply completes sentences. To make it helpful (like ChatGPT), developers train it further on specific Q&A datasets.
-
RLHF (Reinforcement Learning from Human Feedback): Humans rate the model's outputs, teaching it to be safe, polite, and accurate.
6. Inference: The Runtime Execution
When you make an API call, you are triggering Inference. The model takes your input, freezes its weights (it doesn't learn from your prompt in real-time), and runs the data through its layers.
This is where parameters like Temperature come in:
-
Low Temperature (0.1): The model always picks the most probable next token. (Good for coding/math).
-
High Temperature (0.9): The model sometimes picks less probable tokens, introducing "creativity" or randomness.
Conclusion
AI is not magic. It is a massive file of weights and biases processing integer arrays to predict the next number in a sequence.
Understanding this flow, Tokenization → Embedding → Attention → Prediction, allows us to build better software. We can understand why prompts fail, why context windows matter, and how to structure data for RAG systems more effectively.
As we move toward agentic workflows and local LLMs (like GPT-OSS, DeepSeek R1 or other), this fundamental knowledge becomes a requirement for any serious Engineering Leader.
Frequently Asked Questions (FAQs)
Q: Do LLMs "learn" from my API calls in real-time?
Answer: No. When you send a prompt to an API (Inference), the model's weights are frozen. It processes your data to generate a response, but it does not update its long-term memory or "learn" new facts from that specific interaction unless the provider explicitly stores your data for future training batches (which most enterprise agreements prevent).
Q: Why do models "hallucinate" (make things up)?
Answer: Because they are probabilistic, not factual databases. If a model doesn't have the exact answer in its training data, it predicts the next most likely words based on patterns it has seen. If the pattern implies a fact that looks plausible but is false, the model will confidently state it.
Q: What exactly is a "Context Window"?
Answer: The context window is the maximum number of tokens (input + output) the model can hold in its "working memory" at one time. If your conversation exceeds this limit (e.g., 128k tokens), the model "forgets" the earliest parts of the conversation because they literally drop out of the attention mechanism's view.
Q: Why does the same prompt sometimes give different answers?
Answer: This is due to the Temperature setting. If temperature > 0, the model introduces randomness into its token selection process. To get deterministic (identical) results for code or math, you should set the temperature to 0.
References & Further Reading
For developers who want to go deeper into the math and code, here are the primary sources and tools used to understand these concepts:
-
Attention Is All You Need (Google Research)
- The foundational paper from 2017 that introduced the Transformer architecture and changed the industry forever.
-
The Illustrated Transformer (Jay Alammar)
- Widely considered the best visual guide to understanding the mechanics of Attention and Self-Attention.
-
Intro to Large Language Models (Andrej Karpathy)
- A masterclass video by the former Director of AI at Tesla/OpenAI, explaining the "OS" of LLMs.
-
- An interactive tool to see exactly how your text gets converted into integer tokens in real-time.
Subscribe to my newsletter
Read articles from Tech With Asim | Learn, Build, Lead directly inside your inbox. Subscribe to the newsletter, and don't miss out.
More Articles

Assistant API → Responses API: A Complete, Practical Migration Guide (with Next.js & Node examples)
TL;DR: The Responses API gives you simpler request/response semantics, richer streaming events (including function calls), first‑class tool use, and persistent conversations. This guide shows exactly how to migrate a production app—how to handle stre...

Vibe Coding: The Future Every Software Engineer Should Embrace
Introduction We have all seen how fast AI is evolving. From code generation to scaffolding entire modules, tools like ChatGPT, GitHub Copilot, and others are already part of many engineers daily routines. But one approach that stands out and is rapid...
Run DeepSeek R1 Locally with LM Studio – Complete Guide
Introduction AI is evolving rapidly, and while cloud-based AI services are great, they come with privacy concerns, API limits, and server downtime. What if you could run DeepSeek R1 on your own machine without depending on external servers? In this g...